The hardware and bandwidth for this mirror is donated by METANET, the Webhosting and Full Service-Cloud Provider.
If you wish to report a bug, or if you are interested in having us mirror your free-software or open-source project, please feel free to contact us at mirror[@]metanet.ch.
![]()
![]()
![]()
![]()
The goal of textdata is to provide access to text-related data sets for easy access without bundling them inside a package. Some text datasets are too large to store within an R package or are licensed in such a way that prevents them from being included in an OSS-licensed package. Instead, this package provides a framework to download, parse, and store the datasets on the disk and load them when needed.
You can install the not yet released version of textdata from CRAN with:
install.packages("textdata")And the development version from GitHub with:
# install.packages("remotes")
remotes::install_github("EmilHvitfeldt/textdata")The first time you use one of the functions for accessing an included
text dataset, such as lexicon_afinn() or
dataset_sentence_polarity(), the function will prompt you
to agree that you understand the dataset’s license or terms of use and
then download the dataset to your computer.
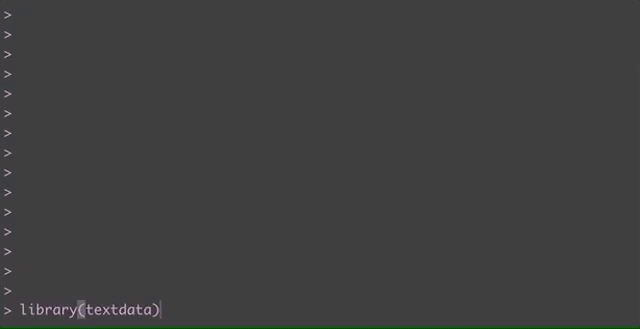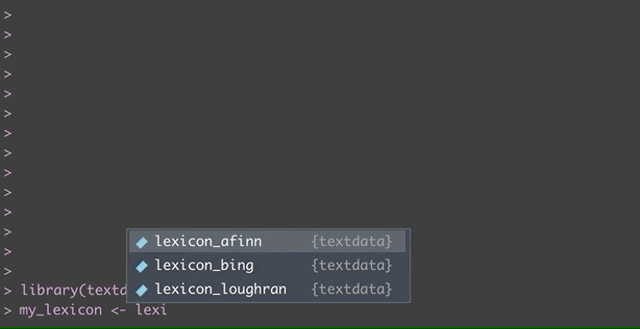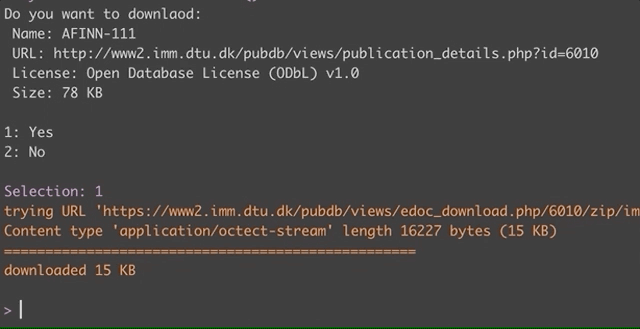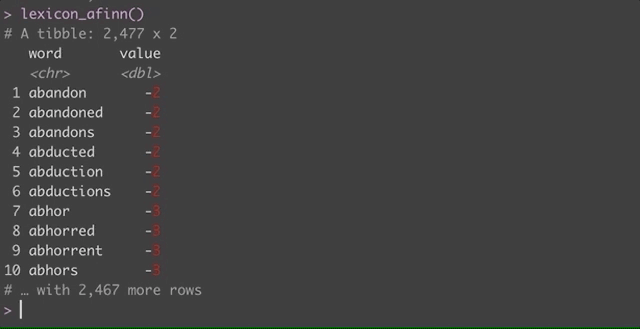
After the first use, each time you use a function like
lexicon_afinn(), the function will load the dataset from
disk.
As of today, the datasets included in textdata are:
| Dataset | Function |
|---|---|
| v1.0 sentence polarity dataset | dataset_sentence_polarity() |
| AFINN-111 sentiment lexicon | lexicon_afinn() |
| Hu and Liu’s opinion lexicon | lexicon_bing() |
| NRC word-emotion association lexicon | lexicon_nrc() |
| NRC Emotion Intensity Lexicon | lexicon_nrc_eil() |
| The NRC Valence, Arousal, and Dominance Lexicon | lexicon_nrc_vad() |
| Loughran and McDonald’s opinion lexicon for financial documents | lexicon_loughran() |
| AG’s News | dataset_ag_news() |
| DBpedia ontology | dataset_dbpedia() |
| Trec-6 and Trec-50 | dataset_trec() |
| IMDb Large Movie Review Dataset | dataset_imdb() |
| Stanford NLP GloVe pre-trained word vectors | embedding_glove6b() |
embedding_glove27b() |
|
embedding_glove42b() |
|
embedding_glove840b() |
Check out each function’s documentation for detailed information (including citations) for the relevant dataset.
Note that this project is released with a Contributor Code of Conduct. By contributing to this project, you agree to abide by its terms. Feedback, bug reports (and fixes!), and feature requests are welcome; file issues or seek support here. For details on how to add a new dataset to this package, check out the vignette!
These binaries (installable software) and packages are in development.
They may not be fully stable and should be used with caution. We make no claims about them.