The hardware and bandwidth for this mirror is donated by METANET, the Webhosting and Full Service-Cloud Provider.
If you wish to report a bug, or if you are interested in having us mirror your free-software or open-source project, please feel free to contact us at mirror[@]metanet.ch.
The baserater package allows to:
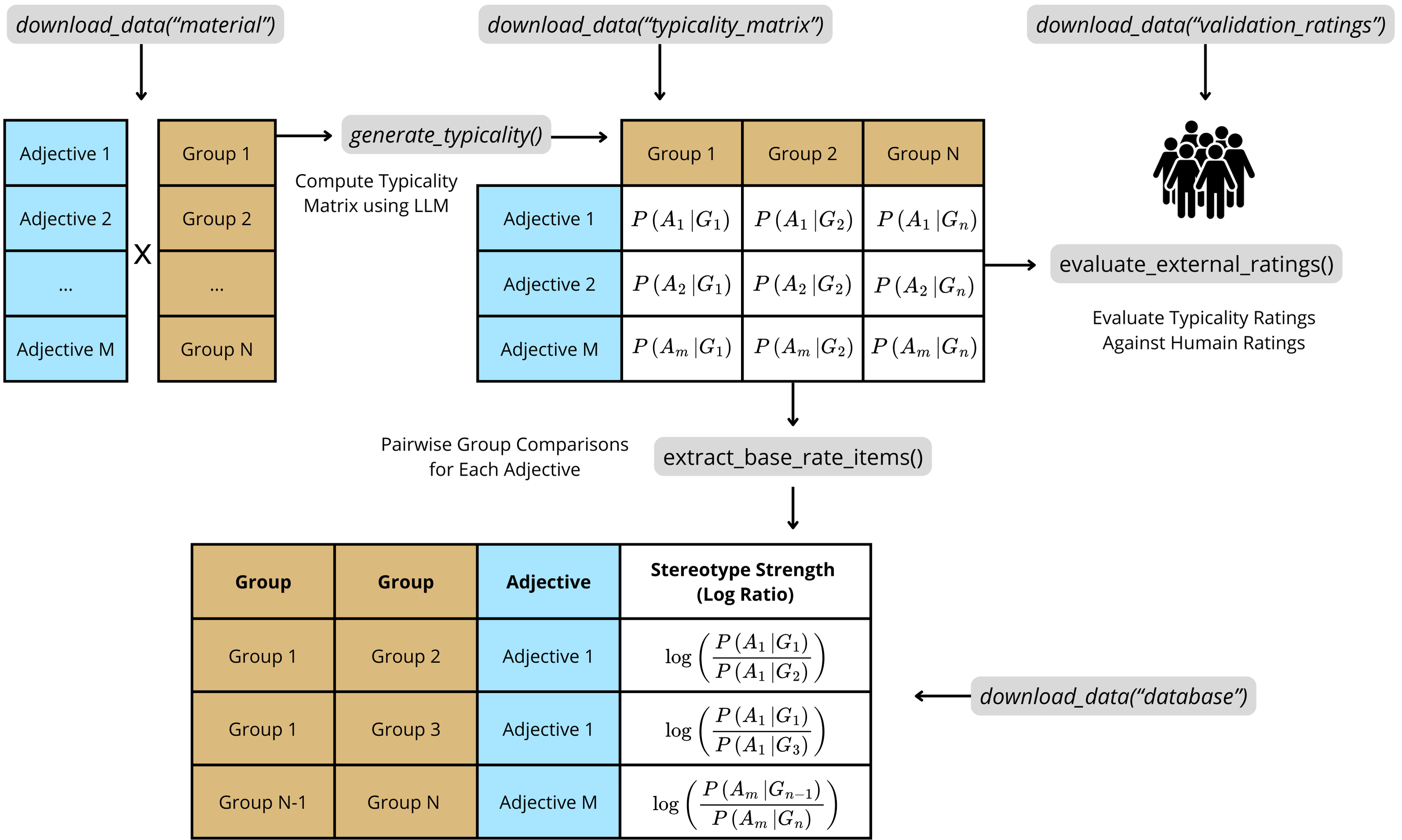
It is designed to streamline the creation of base-rate neglect items for reasoning experiments. A base-rate neglect item typically involves two groups (e.g., “engineers” and “construction workers”) and a descriptive trait (e.g., “nerdy”). Participants are presented with statistical information (base-rates; e.g., “There are 995 construction workers and 5 engineers”) and stereotypical information (the descriptive trait). Their task is to decide the most likely group membership of an individual described by that trait. The “typicality rating” generated by large language models quantifies how strongly certain traits (e.g., “nerdy,” “kind”) or descriptions are (stereo)typically associated with specific groups (e.g., engineers, nurses). This allows researchers to precisely measure and control “stereotype strength”–the extent to which a given description is perceived as belonging more strongly to one group over another (e.g., the trait “nerdy” is typically seen as more characteristic of engineers than of construction workers).
The full documentation along with a tutorial is available at: https://jeremie-beucler.github.io/baserater/
To learn more about the theoretical framework and studies underlying the ‘baserater’ package, see the paper: Using Large Language Models to Estimate Belief Strength in Reasoning (Beucler et al., 2025), available at https://doi.org/10.31234/osf.io/eqrfu_v1.
To install the package, run:
install.packages("baserater")
# Alternatively, install via devtools
# install.packages("devtools") # if not yet installed
devtools::install_github("Jeremie-Beucler/baserater")Please cite the package as:
Beucler, J. (2025). baserater: An R package using large language models to estimate belief strength in reasoning. R package version 0.1.2. https://doi.org/10.32614/CRAN.package.baserater
Schematic overview of the ‘baserater’ package.
MIT
The baserater package can connect to various inference
providers such as ‘Together AI’, ‘Hugging Face’ Inference, ‘Fireworks’,
and ‘Replicate’.
These platforms host or serve large language models and allow you to
query them through a standard style chat/completions
API.
Here are some useful resources to get started:
Before generating new scores using the
generate_typicality() function, make sure you have
completed the following setup steps:
Obtain your provider’s API URL and token:
You can pass them directly to the function or store them as environment
variables in R, for example:
Sys.setenv(PROVIDER_API_URL = "https://api.together.xyz/v1/chat/completions")
Sys.setenv(PROVIDER_API_TOKEN = "your_secret_token")
Check model availability and license
terms:
Some models require that you accept license terms before use. Check your
provider’s model catalog for details.
Verify the correct model name for your
provider:
Model identifiers can differ between providers (for example,
"meta-llama/Llama-3.3-70B-Instruct-Turbo" on ‘Together AI’
vs. "meta-llama/Llama-3.3-70B-Instruct" on ‘Hugging
Face’).
Always use the exact model name listed in your provider’s
documentation.
These binaries (installable software) and packages are in development.
They may not be fully stable and should be used with caution. We make no claims about them.