The hardware and bandwidth for this mirror is donated by METANET, the Webhosting and Full Service-Cloud Provider.
If you wish to report a bug, or if you are interested in having us mirror your free-software or open-source project, please feel free to contact us at mirror[@]metanet.ch.
Bayesian Estimation of Naloxone Numbers Underreporting (BENNU)
The package name comes from the Welsh word for “to finish” (pronounced benn-y)
![]()
![]()
![]()

An R package 📦 for generating estimates of total naloxone kit numbers distributed and used from naloxone kit orders data.
You can install the released version of bennu from CRAN with:
install.packages("bennu")And the development version from GitHub with:
# install.packages("devtools")
devtools::install_github("sempwn/bennu")This example runs output for test data generated by the package:
library(bennu)
library(rstan)
#> Loading required package: StanHeaders
#>
#> rstan version 2.32.7 (Stan version 2.32.2)
#> For execution on a local, multicore CPU with excess RAM we recommend calling
#> options(mc.cores = parallel::detectCores()).
#> To avoid recompilation of unchanged Stan programs, we recommend calling
#> rstan_options(auto_write = TRUE)
#> For within-chain threading using `reduce_sum()` or `map_rect()` Stan functions,
#> change `threads_per_chain` option:
#> rstan_options(threads_per_chain = 1)
library(bayesplot)
#> This is bayesplot version 1.14.0
#> - Online documentation and vignettes at mc-stan.org/bayesplot
#> - bayesplot theme set to bayesplot::theme_default()
#> * Does _not_ affect other ggplot2 plots
#> * See ?bayesplot_theme_set for details on theme setting
rstan_options(auto_write = TRUE)
options(mc.cores = parallel::detectCores(logical = FALSE))
## basic example code
d <- generate_model_data()
# note iter should be at least 2000 to generate a reasonable posterior sample
fit <- est_naloxone(d,iter=500)
mcmc_pairs(fit, pars = c("sigma","mu0","zeta"),
off_diag_args = list(size = 1, alpha = 0.5))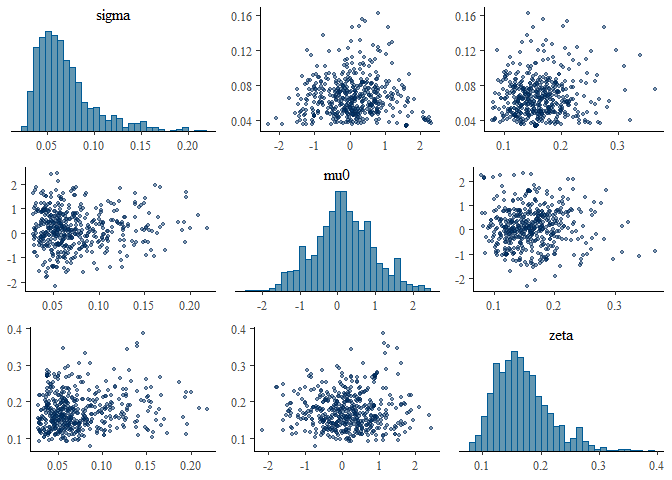
An overall summary of the model output can also be provided as a data frame
kit_summary_table(fit, data = d)
#> # A tibble: 1 × 6
#> Probability of kit use if dist…¹ Estimated as distrib…² Proportion kits dist…³
#> <glue> <glue> <glue>
#> 1 64.97% (95% CrI: 12.93% - 96.79… 24,907.00 (95% CrI: 2… 21.03% (95% CrI: 20.8…
#> # ℹ abbreviated names: ¹`Probability of kit use if distributed`,
#> # ²`Estimated as distributed`,
#> # ³`Proportion kits distributed that are reported`
#> # ℹ 3 more variables: `Estimated kits used` <glue>,
#> # `Proportion kits used that are reported` <glue>,
#> # `Proportion kits ordered that are used` <glue>If you encounter a clear bug, please file an issue with a minimal reproducible example on GitHub.
These binaries (installable software) and packages are in development.
They may not be fully stable and should be used with caution. We make no claims about them.