The hardware and bandwidth for this mirror is donated by METANET, the Webhosting and Full Service-Cloud Provider.
If you wish to report a bug, or if you are interested in having us mirror your free-software or open-source project, please feel free to contact us at mirror[@]metanet.ch.
![]()
![]()
![]()
![]()
![]()
The observant reader has already identified the brilliant word play
on Psalm 72:8 (King James Version): “He shall have dominion also from
sea to sea, and from the river unto the ends of the
earth”. c2z aims at obtaining total dominion over
Cristin (Current Research
Information SysTem in Norway) and Zotero. The package enables
manipulating Zotero libraries using R. Import, in batch,
references from Cristin, regjeringen.no, CRAN, ISBN (currently, Alma and
Library of Congress), and DOI (currently, CrossRef and DataCite) to a
Zotero library. Add, edit, copy, or delete items, including attachments
and collections, and export references to BibLaTeX (and other formats)
directly in R (see Figure 1).

Figure 1. c2z flowchart.
Anyone using Zotero, or similar reference management software. However, the project is probably of extra interest to researchers, students, bibliomaniacs and others working in library-type services. Though the project is grounded in a Norwegian context (with apologizes to Åse Wetås for writing the documentation in (American) English), international publications are easily available through DOI and ISBN, and the Zotero functions are independent of acquiring metadata from external services.
Should you require a specific international/national/regional library or database, please make a request here or open a pull request. The only requirement is that the library services have open access and serve MARC 21 / DOI type metadata (or has fairly structured XML/JSON). Okay, okay, there are no requirements, I’ll look into any request and try to make it work.
Hoarding references in Zotero, obviously. However,
c2z also has more practical purposes, especially
in combination with other packages. You are probably the right kind of
weirdo (since you are reading this) and you could use
c2z to easily handle your references while writing
and preparing manuscripts (e.g., papaja), or for use on a
(personal) webpage (e.g., blogdown or bookdown). If you need to
work for a living, or just like to show off, you could automate the
publication list for your résumé (e.g., vitae). If the Man
pays you to keep track of publications, you could schedule a script
(e.g., cronR, taskscheduleR or
Github Actions) to keep track of new publications from an institution or
research group and email you (or the Man) recent publications on a
monthly or weekly (or hourly) basis (e.g., emayili or mailR). If you really
feel like it you could use Home
Assistant to play Tina Turner - The
Best (Official Music Video) whenever one of your publications is
registered on Cristin.
The sky is the limit!
The project strives at keeping the number of dependencies at a
minimum. However, c2z is highly dependent on dplyr, httr, purrr, rvest, tibble, and jsonlite.
Dependencies are automatically installed from CRAN. By default, outdated dependencies are automatically upgraded.
You probably want to access a restricted Zotero library. Please see
the
short tutorial on how to create a Zotero API key and how to define
it in your .Renviron.
You can install c2z from GitHub. If you already
have a previous version of c2z installed, using
the command below will update to the latest development version.
devtools::install_github("oeysan/c2z")Please note that stable versions are hosted at CRAN, whereas GitHub versions are in active development.
utils::install.packages("c2z")Also, please see the magnificent vignette and other documentation.
I work as an associate professor at a department of teacher education
in Norway. Doing so, one of my responsibilities is surprisingly enough
teaching. Even more surprising, most of the literature is in Norwegian,
and in the form of monographs or anthologies. Unfortunately, Zotero is
not well-adapted to importing Norwegian books through ISBN (see Figure
2). In the example below, Imsen (2020) is imported using the Zotero
magic wand (left) and c2z (right). Similarly,
Zotero is unable to import Johannessen et al. (2021) using ISBN
(cf. lookup failed). Evidently, Alma (47BIBSYS) is superior to Open
WorldCat and similar when it comes to identifying (most) Norwegian
books.
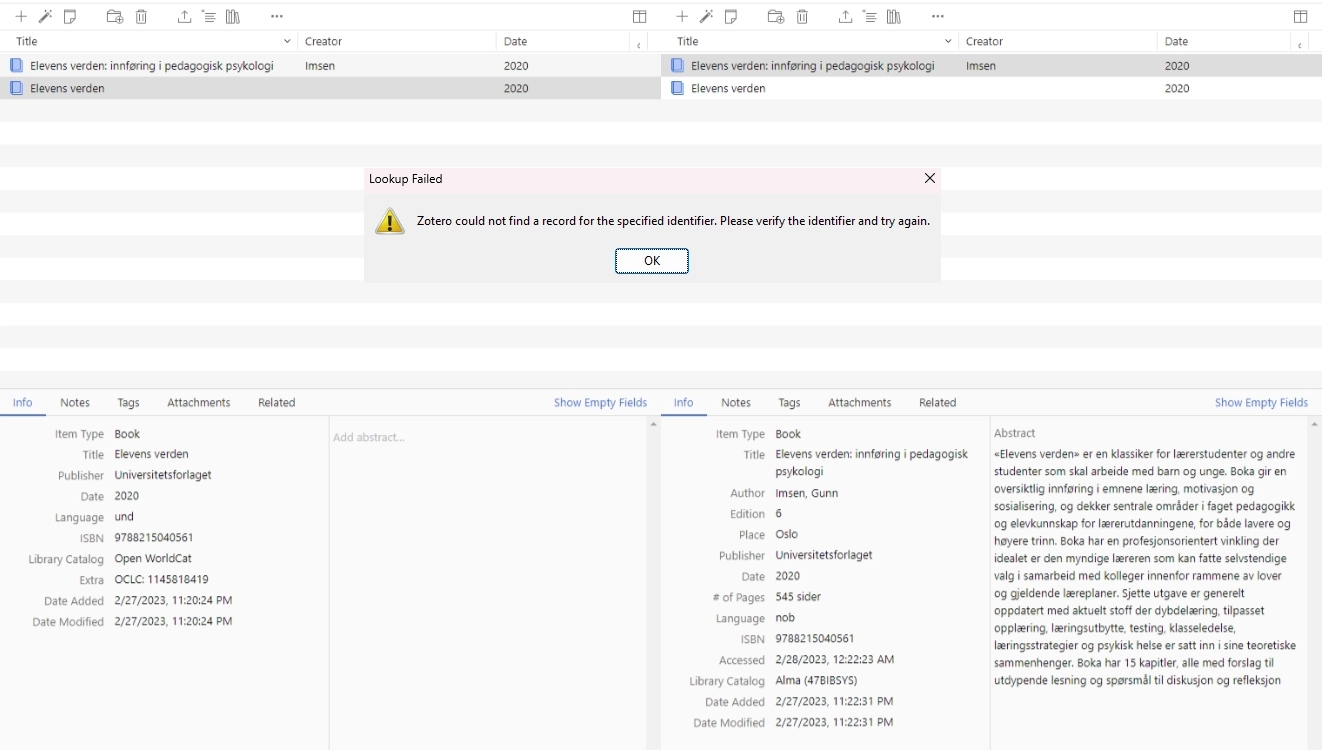
Figure 2. Zotero vs. c2z example.
The following example of c2z addresses this
issue, and the Zotero function act as a wrapper by 1)
connecting to the Zotero API, 2) creating a collection called
“c2z-example”, 3) search for items using two ISBN identifiers
(i.e. Imsen, 2020; Johannessen et al., 2021), 4) posting the items to
the defined collection, 5) exporting the items as BibLaTeX and creating
a bibliography in HTML format using the APA7 reference style, and 6)
cleaning up the example by deleting the collection and the two items.
The R output is rather noisy and can be disabled by adding
silent = TRUE.
library(c2z)
example <- Zotero(
collection.names = "c2z-example",
library = TRUE,
library.type = "data,bib",
create = TRUE,
isbn = c("9788215040561", "9788279354048"),
post = TRUE,
post.collections = FALSE,
export = TRUE,
style = "apa-single-spaced",
delete = TRUE,
delete.collections = TRUE,
delete.items = TRUE,
index = TRUE
)
#> Searching for collections
#> Found 0 collections
#> Adding 1 collection to library using 1 POST request
#> —————————————————Process: 100.00% (1/1). Elapsed time: 00:00:00—————————————————
#> $post.status.collections
#> # A tibble: 1 × 2
#> status key
#> <fct> <chr>
#> 1 success V8BCATZM
#>
#> $post.summary.collections
#> # A tibble: 1 × 2
#> status summary
#> <fct> <int>
#> 1 success 1
#>
#>
#> The Zotero list contains: 1 collection, 0 items, and 0 attachments
#> Searching 2 items using ISBN
#> Adding 2 items to library using 1 POST request
#> —————————————————Process: 100.00% (1/1). Elapsed time: 00:00:01—————————————————
#> $post.status.items
#> # A tibble: 2 × 2
#> status key
#> <fct> <chr>
#> 1 success X3KYHW7U
#> 2 success T9LJ727I
#>
#> $post.summary.items
#> # A tibble: 1 × 2
#> status summary
#> <fct> <int>
#> 1 success 2
#>
#>
#> Searching for items using 1 collection
#> Found 2 items
#> The Zotero list contains: 1 collection, 2 items, and 0 attachments
#> Found 2 `biblatex` references
#> Deleting 1 collection using 1 DELETE request
#> —————————————————Process: 100.00% (1/1). Elapsed time: 00:00:00—————————————————
#> Deleting 2 items using 1 DELETE request
#> —————————————————Process: 100.00% (1/1). Elapsed time: 00:00:00—————————————————
#> Creating index for itemsThe example will yield the following HTML output:
Johannessen et al. (2021) is an interesting (well, perhaps not
interesting to all people) example of the nasty business that is
metadata. In Cristin the authors are listed as Christoffersen,
Johannessen, and Tufte, in Alma the authors are listed as
Johannessen, Christoffersen, and Tufte, whereas the book itself
list the authors as Johannessen, Tufte, and Christoffersen
(interesting, right?). c2z amends the conflicting
results provided by Cristin and Alma by parsing the statement of
responsibility field (if it exists) in MARC 21.
Despite several innovative, creative and valiant efforts to mitigate
common weaknesses in CrossRef, DataCite, MARC 21, and especially
Cristin, c2z cannot always create order in a
chaotic metadata world. A major limitation of any reference management
software scraping metadata through databases is poorly registered data.
GIGO
will happen and manual inspection is required to assure that the
references are correct.
Moreover, the project stands or falls by its relationship with the
API’s, meaning that c2z is likely a high
maintenance project. For instance, Cris/NVA is planned to replace
Cristin during 2023, which is likely to cause some headache.
Finally (not really, there are probably several other limitations),
c2z is not built for speed. The project tries to
wrangle data from strange and exotic beasts, while simultaneously hoping
to avoid exploding kittens. Isolated, wrangling data from Cristin, ISBN,
or DOI is not very time-consuming (though downloading the entire Cristin
database (> 300 MB) and importing to Zotero will take some time). One
reason is that Cristin for some reason keeps a separate table containing
contributors, meaning that each reference needs two API calls. Book
chapters are even more time-consuming, as Cristin also keeps the book
metadata in another table, totaling four (4) API calls.
Enabling data-augmentation through DOI or ISBN demands even more API
calls, and if Crossref search is enabled, with no prior identification
through DOI or ISBN, the process can take a long, long time. (… and
totally hammer the Crossref API, please don’t do it!). For example,
downloading and converting 50 random items (n = 1600) from each
of the, for now, supported Cristin categories (k = 32), takes
approximately 3.12 minutes without any augmentation, 39.02 minutes with
DOI/ISBN look-up, and 177.54 minutes with Crossref search enabled.
Please note that run-time is dependent on bandwidth and the
response-time for the API’s (Alma has especially high latency), and that
c2z uses exponential backoff depending on the API
response.
Please report any bugs/issues/requests here, and feel to make a pull request.
Your R code seems to be a mash-up of different styles, not adhering to Google’s R style guide or Tidyverse’s style guide. In addition, you combine both HTML/CSS/JS and Markdown, violating the Markdown philosophy. What’s your thought on this breach of tradition?
– “Thank you, but I prefer it my way.”
Don’t be evil. Please read the Code of Conduct
This project is licensed under the MIT License - see LICENSE for details
Henrik Karlstrøm for his work on rcristin
These binaries (installable software) and packages are in development.
They may not be fully stable and should be used with caution. We make no claims about them.