
The hardware and bandwidth for this mirror is donated by METANET, the Webhosting and Full Service-Cloud Provider.
If you wish to report a bug, or if you are interested in having us mirror your free-software or open-source project, please feel free to contact us at mirror[@]metanet.ch.
![]()
stacks is an R package for model stacking that aligns with the tidymodels. Model stacking is an ensembling method that takes the outputs of many models and combines them to generate a new model—referred to as an ensemble in this package—that generates predictions informed by each of its members.
The process goes something like this:
data_stack object with
stacks()data_stack with add_candidates()blend_predictions()fit_members()predict()You can install the package with the following code:
install.packages("stacks")Install the development version with:
# install.packages("pak")
pak::pak("tidymodels/stacks")stacks is generalized with respect to:
stacks uses a regularized linear model to combine predictions from ensemble members, though this model type is only one of many possible learning algorithms that could be used to fit a stacked ensemble model. For implementations of additional ensemble learning algorithms, check out h2o and SuperLearner.
Rather than diving right into the implementation, we’ll focus here on
how the pieces fit together, conceptually, in building an ensemble with
stacks. See the basics vignette for an example
of the API in action!
At the highest level, ensembles are formed from model definitions. In this package, model definitions are an instance of a minimal workflow, containing a model specification (as defined in the parsnip package) and, optionally, a preprocessor (as defined in the recipes package). Model definitions specify the form of candidate ensemble members.

To be used in the same ensemble, each of these model definitions must
share the same resample. This rsample rset
object, when paired with the model definitions, can be used to generate
the tuning/fitting results objects for the candidate ensemble
members with tune.

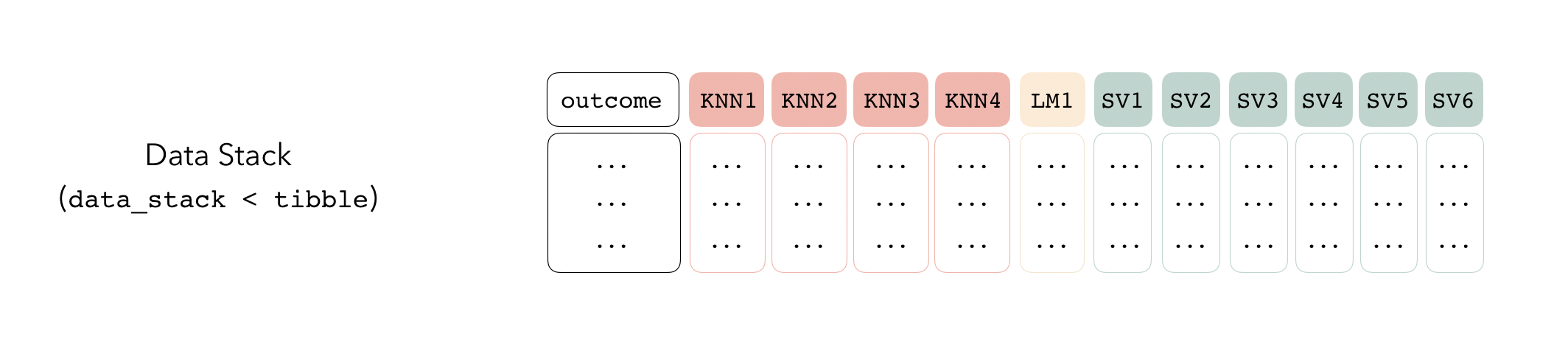
Candidate members first come together in a data_stack
object through the add_candidates() function. Principally,
these objects are just tibbles, where the first column
gives the true outcome in the assessment set (the portion of the
training set used for model validation), and the remaining columns give
the predictions from each candidate ensemble member. (When the outcome
is numeric, there’s only one column per candidate ensemble member.
Classification requires as many columns per candidate as there are
levels in the outcome variable.) They also bring along a few extra
attributes to keep track of model definitions.
Then, the data stack can be evaluated using
blend_predictions() to determine to how best to combine the
outputs from each of the candidate members. In the stacking literature,
this process is commonly called metalearning.
The outputs of each member are likely highly correlated. Thus, depending on the degree of regularization you choose, the coefficients for the inputs of (possibly) many of the members will zero out—their predictions will have no influence on the final output, and those terms will thus be thrown out.

These stacking coefficients determine which candidate ensemble
members will become ensemble members. Candidates with non-zero stacking
coefficients are then fitted on the whole training set, altogether
making up a model_stack object.
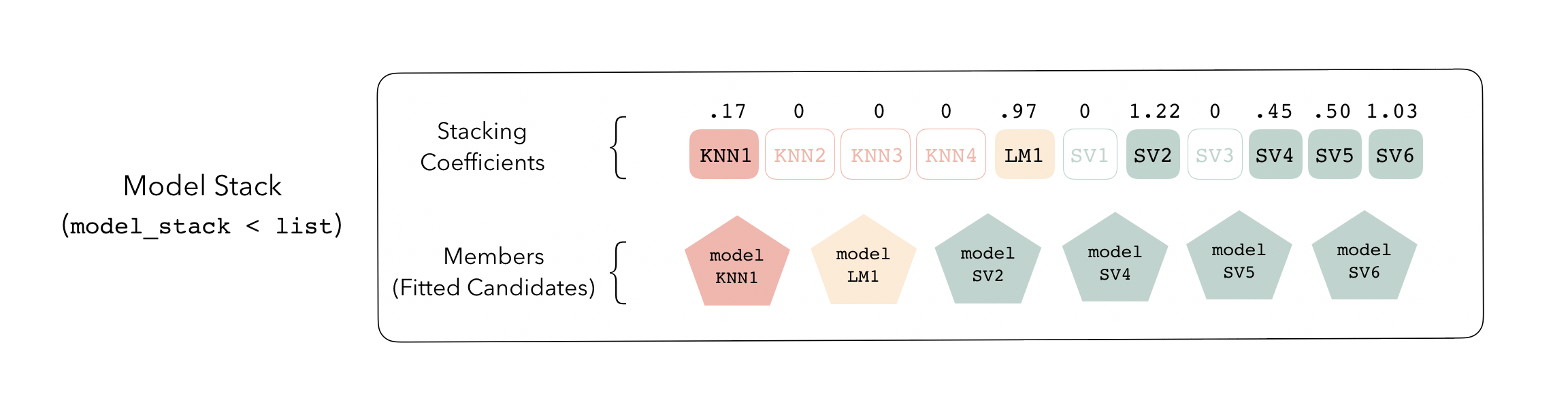
This model stack object, outputted from fit_members(),
is ready to predict on new data! The trained ensemble members are often
referred to as base models in the stacking literature.
The full visual outline for these steps can be found here.
The API for the package closely mirrors these ideas. See the
basics vignette for an example of how this grammar is
implemented!
This project is released with a Contributor Code of Conduct. By contributing to this project, you agree to abide by its terms.
For questions and discussions about tidymodels packages, modeling, and machine learning, please post on Posit Community.
If you think you have encountered a bug, please submit an issue.
Either way, learn how to create and share a reprex (a minimal, reproducible example), to clearly communicate about your code.
Check out further details on contributing guidelines for tidymodels packages and how to get help.
In the stacks package, some test objects take too long to build with
every commit. If your contribution changes the structure of
data_stack or model_stacks objects, please
regenerate these test objects by running the scripts in
man-roxygen/example_models.Rmd, including those with chunk
options eval = FALSE.
These binaries (installable software) and packages are in development.
They may not be fully stable and should be used with caution. We make no claims about them.
{kind=link}