The hardware and bandwidth for this mirror is donated by METANET, the Webhosting and Full Service-Cloud Provider.
If you wish to report a bug, or if you are interested in having us mirror your free-software or open-source project, please feel free to contact us at mirror[@]metanet.ch.
![]()
![]()
![]()
High-level functions for tabulating, charting and reporting survey data.

# Install the package (see below), then load it
library(volker)
# Load example data from the package
data <- volker::chatgpt
# Create your first table and plot, counting answers to an item battery
report_counts(data, starts_with("cg_adoption_social"))
# Create your first table and plot, reporting mean values of the item battery
report_metrics(data, starts_with("cg_adoption_social"))See further examples in
vignette("introduction", package="volker").
Don’t miss the template feature: Within RStudio, create a new
Markdown document, select From template, choose and finally
knit the volkeR Report! It’s a blueprint for your own
tidy reports.
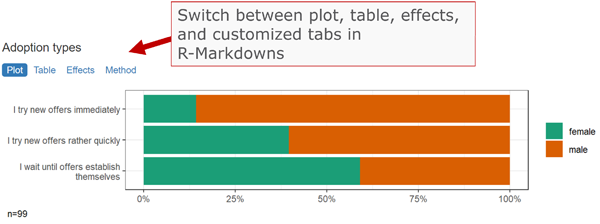
The volkeR package is made for creating quick and easy overviews about datasets. It handles standard cases with a handful of functions. Basically you select one of the following functions and throw your data in:
report_counts()report_metrics()The report functions combine tables, plots and, optionally, effect size calculations. To request only one of those outputs, directly use the respective function:
plot_metrics() and
plot_counts()tab_metrics() and
tab_counts()effect_metrics() and
effect_counts()Which one is best? That depends on your objective:
Table or plot?
A plot is quick to capture, data from a table is better for further
calculations. Functions for tables start with tab,
functions for plots with plot. If in doubt, create both at
once with the report-functions.
Categorical or metric variables?
Categories can be counted, for metric variables distribution parameters
such as the mean and standard deviation are calculated. Functions for
categorical variables contain counts in their name, those
for metric metrics.
Individual, grouped or correlated?
Groups can be compared (e.g., the average age by gender) or
cross-tabulated (e.g. combinations of education level and gender) by
providing a grouping column as third parameter of table, plot and report
functions. To calculate correlations and show scatter plots, provide a
metric column and set the metric-Paramter to TRUE. The effect-functions
calculate effect sizes and statistical tests for group comparisons and
correlations.
One variable or item batteries?.
Item batteries are often used in surveys. Each item results in a single
variable, but the variables are all measured with the same scale (e.g. 1
= not at all to 5 = fully applies). To summarise multiple items send a
column selection to the functions by using tidyselect mechanisms such as
starts_with().
Markdown or data frame?
All table functions return data frames that can be processed further.
The tables have their own print function, so the output of all functions
can be used directly in Markdown documents to display neatly formatted
tables and plots. The report-functions create tidy
interactive tabsheets to switch between plots, tables, and
indexes.
| Metric | Categorical | |
| One variable |
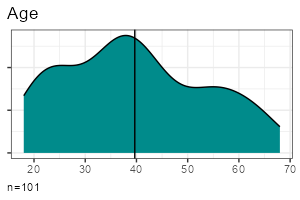
|
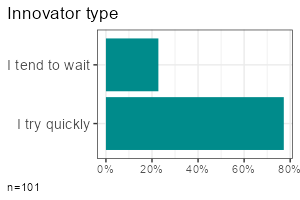
|
| Group comparison |
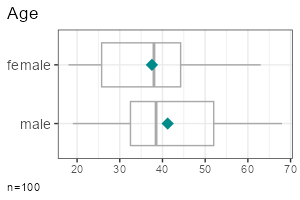
|
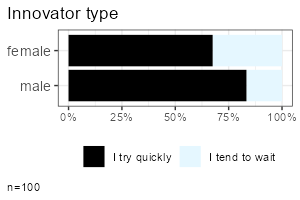
|
| Multiple items |
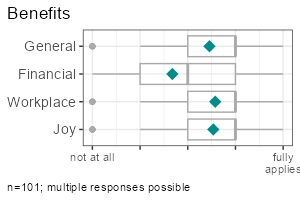
|
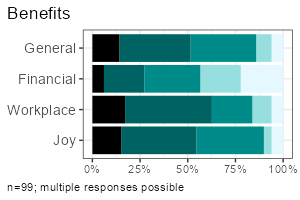
|
All functions take a data frame as their first argument, followed by a column selection, and optionally a grouping column. Reproduce the examples above:
report_metrics(data, sd_age)report_counts(data, sd_gender)report_metrics(data, sd_age, sd_gender)report_counts(data, adopter, sd_gender)report_metrics(data, starts_with("cg_adoption"))report_counts(data, starts_with("cg_adoption"))The column selections determine which type of output is generated. In
the second parameter (after the dataset), you can either provide a
single column or a selection of multiple items. To compare groups,
provide an additional categorical column in the third parameter. To
calculate correlations, provide a metric column in the third parameter
and set the metric parameter to TRUE.
Note: Some column combinations are not implemented yet.
Calculate effect sizes and conduct basic statistical tests using
effect_counts() and effect_metrics(). Effect
calculation is included in the reports if you request it by the
effect-parameter, for example:
report_counts(data, adopter, sd_gender, prop = "cols", effect = TRUE)A word of warning: Statistics is the world of uncertainty. All procedures require mindful interpretation. Counting stars might evoke illusions.
You can generate tables and plots for clustering and factor analysis of metric variables. Both clustering and factor analysis are included in the reports when requested using the factors or clusters parameters.
Set the respective parameters to TRUE to generate a scree plot and let the diagnostics choose the optimal number:
report_metrics(data, starts_with("cg_adoption"), factors = TRUE, clusters = TRUE)Set the desired number directly:
report_metrics(data, starts_with("cg_adoption"), factors = 3, clusters = 4)You don’t need to add both parameters at the same time if you are only interested in factors or clusters.
Modeling in the statistical sense is predicting an outcome (dependent variable) from one or multiple predictors (independent variables).
The report_metrics() function calculates a linear model if the
model parameter is set to TRUE. You provide
the variables in the following parameters:
metric parameter (a tidy
column selection).interactions parameter with a
vector of multiplication terms
(e.g. c(sd_age * sd_gender)).ds |>
filter(sd_gender != "diverse") |>
report_metrics(
use_work,
cross = c(sd_gender, adopter),
metric = sd_age,
model = TRUE, diagnostics = TRUE
)If you are used to formulas, you can provide your model in formula
notation instead of using column selections. This automatically enables
the model parameter. The following example is equivalent to
the preceding example:
ds |>
filter(sd_gender != "diverse") |>
report_metrics(use_work ~ sd_gender + adopter + sd_age)Four selected diagnostic plots are generated if the
diagnostics parameter is set to TRUE:
To work with the predicted values, use add_model()
instead of the report function. This will add a new variable prefixes
with prd_, holding the target scores.
ds <- ds |> add_model(
use_work,
categorical = c(sd_gender, adopter),
metric = sd_age
)
report_metrics(ds, use_work, prd_use_work, metric = T)There are two functions to get the regression table or plot from the new column:
model_tab(ds, prd_use_work)
model_plot(ds, prd_use_work)By default, p-values are adjusted to the number of tests by
controlling the false discovery rate (fdr). Set the adjust
parameter to FALSE to disable p-value correction.
In content analysis, reliability is usually checked by coding the cases with different persons and then calculating the overlap. To calculate reliability scores, prepare one data frame for each person:
TRUE/FALSE) or
contain a fixed number of values such as “sports”, “politics”,
“weather”.Next, you row-bind the data frames. The coder and ID columns ensure that each coding can be uniquely matched to both the coder and the case.
data_coded <- bind_rows(
data_coder1,
data_coder2
)The final data, for example, looks like:
| case | coder | topic_sports | topic_weather |
|---|---|---|---|
| 1 | anne | TRUE | FALSE |
| 2 | anne | TRUE | FALSE |
| 3 | anne | FALSE | TRUE |
| 1 | ben | TRUE | TRUE |
| 2 | ben | TRUE | FALSE |
| 3 | ben | FALSE | TRUE |
Calculating reliability is straightforward with
report_counts():
starts_with()) to the second parameter.ids parameter to the column that contains case
IDs or case numbers (this tells the volker-package which cases belong
together).agree parameter to “reliability” to request
reliability scores.Example:
report_counts(data_coded, starts_with("topic_"), coder, ids = case, prop = "cols", agree = "reliability")If you are only interested in the scores (without a plot), use
agree_tab. Tip: You may abbreviate the method name (e.g.,
“reli” instead of “reliability”).
agree_tab(data_coded, starts_with("topic_"), coder, ids = case, method = "reli")You can also request classification performance indicators (accuracy,
precision, recall, F1) with the same function by setting the
method parameter to “classification” (may be abbreviated).
Use this option when comparing manual codings with automated codings
(e.g., classifiers or large language models). By default, you get macro
statistics (average precision, recall and f1 across categories).
If you have multiple values in a column, you can focus on one category to get micro statistics:
agree_tab(data_coded, starts_with("topic_"), coder, ids = case, method = "class", category = "catcontent")One of the strongest package features is labeling. You know the pain.
Labels are stored in the column attributes. Inspect current labels of
columns and values by the codebook()-function:
codebook(data)This results in a table with item names, item values, value names and value labels.
You can set specific column labels by providing a named list to the
items-parameter of labs_apply():
data %>%
labs_apply(
items = list(
"cg_adoption_advantage_01" = "General advantages",
"cg_adoption_advantage_02" = "Financial advantages",
"cg_adoption_advantage_03" = "Work-related advantages",
"cg_adoption_advantage_04" = "More fun"
)
) %>%
tab_metrics(starts_with("cg_adoption_advantage_"))Labels for values inside a column can be adjusted by providing a
named list to the values-parameter of labs_apply(). In
addition, select the columns where value labels should be changed:
data %>%
labs_apply(
cols = starts_with("cg_adoption"),
values = list(
"1" = "Strongly disagree",
"2" = "Disagree",
"3" = "Neutral",
"4" = "Agree",
"5" = "Strongly agree"
)
) %>%
plot_metrics(starts_with("cg_adoption"))To conveniently manage all labels of a dataset, save the result of
codebook() to an Excel file, change the labels manually in
a copy of the Excel file, and finally call labs_apply()
with your revised codebook.
library(readxl)
library(writexl)
# Save codebook to a file
codes <- codebook(data)
write_xlsx(codes,"codebook.xlsx")
# Load and apply a codebook from a file
codes <- read_xlsx("codebook_revised.xlsx")
data <- labs_apply(data, codes)Be aware that some data operations such as mutate() from
the tidyverse loose labels on their way. In this case, store the labels
(in the codebook attribute of the data frame) before the operation and
restore them afterwards:
data %>%
labs_store() %>%
mutate(sd_age = 2024 - sd_age) %>%
labs_restore() %>%
tab_metrics(sd_age)The labeling mechanisms follow a technique used, for example, on SoSci Survey. Sidenote for techies: Labels are stored in the column attributes. That’s why you can directly throw in labeled data from the SoSci Survey API:
library(volker)
# Get your API link from SoSci Survey with settings "Daten als CSV für R abrufen"
eval(parse("https://www.soscisurvey.de/YOURPROJECT/?act=YOURKEY&rScript", encoding="UTF-8"))
# Generate reports
report_counts(ds, A002)For best results, use sensible prefixes and captions for your SoSci questions. The labels come directly from your questionnaire.
Please note: The values -9, -2,
-1 and [NA] nicht beantwortet,
[NA] keine Angabe, [no answer] are
automatically recoded to missing values within all plot, tab, effect,
and report functions. See the clean-parameter help how to disable
automatic residual removal.
You can change plot colors using the
theme_vlkr()-function:
theme_set(
theme_vlkr(
base_fill = c("#F0983A","#3ABEF0","#95EF39","#E35FF5","#7A9B59"),
base_gradient = c("#FAE2C4","#F0983A")
)
)Plot and table functions share a number of parameters that can be used to customize the outputs. Lookup the available parameters in the help of the specific function.
options(vlkr.na.numbers=FALSE) and
options(vlkr.na.levels=FALSE). Rows with missing values in
the analyzed columns are, by default, removed before producing tables or
plots. To prevent this and to use the maximum available information,
call options(vlkr.na.omit=FALSE). From this point on, for
example, item summaries are calculated using all values available for
each single item. The outputs contain hints about cases with missing
data.add_index() or, using the
index-parameter, automatically be included in report functions.
Cronbach’s alpha is added to all table outputs.add_factors() new
columns are added. The factors-parameter in the report_metrics function
automatically adds a factor analysis to the outputs.add_clusters() a new column
indicating cluster groups is added. The clusters-parameter in the
report_metrics function automatically adds a cluster analysis to the
outputs.report_counts()), you can choose
between Cramer’s V (items are compared with items) or NPMI (the single
item values are compared). In this case, we recommend to also set the
tiles-parameter to TRUE for generating a heatmap (the default are bar
plots). Normalized pointwise mutual information helps spotting
combinations that are more rare (negative values) or more frequent
(positive values) than expected by chance. You can add “npmi” to the
numbers parameter to plot the values on the tiles.As with all other packages you’ll have to install the package first.
install.packages("strohne/volker")You can try alternative versions:
If you want, install the main version from GitHub using remotes, which may include features not yet published on CRAN (if asked, skip the updates):
if (!require(remotes)) { install.packages("remotes") }
remotes::install_github("strohne/volker", upgrade="never", build_vignettes = TRUE)In case you are adventurous, try the latest experimental development version which lives in the devel branch (if asked, skip the updates):
if (!require(remotes)) { install.packages("remotes") }
remotes::install_github("strohne/volker", ref="devel", upgrade="never", build_vignettes = TRUE)codebook() to see all labels
present in a dataset.volker::html_report
template in your Markdown documents to switch between tables and plots
when using the report-functions.The kableExtra package produces an error in R 4.3 when knitting
documents:
.onLoad in loadNamespace() für 'kableExtra' fehlgeschlagen.
As a work around, remove PDF and Word settings from the output options
in you markdown document (the yml section at the top). Alternatively,
install the latest development version:
remotes::install_github("kupietz/kableExtra")| Version | Features | Status |
|---|---|---|
| 1.0 | Descriptives | 90% done |
| 2.0 | Effects | 75% done |
| 3.0 | Factors & clusters | 80% done |
| 4.0 | Linear models | 50% done |
| 5.0 | Text analysis | work in progress |
The volker package is inspired by outputs used in the textbook Einfache Datenauswertung mit R (Gehrau & Maubach et al., 2022), which provides an introduction to univariate and bivariate statistics and data representation using RStudio and R Markdown.
Other packages with high-level reporting functions:
- https://github.com/tidycomm/tidycomm
- https://github.com/kassambara/rstatix
- https://github.com/easystats/easystats
Authors
Jakob Jünger (University of Münster)
Henrieke Kotthoff (University of Münster)
Contributors
Chantal Gärtner (University of Münster)
Sophia Rinne (University of Münster)
Citation
Jünger, J. & Kotthoff, H. (2024). volker: High-level functions for
tabulating, charting and reporting survey data. R package version
3.0.
These binaries (installable software) and packages are in development.
They may not be fully stable and should be used with caution. We make no claims about them.